Abstract #
As organisations look to new methodologies to increase, test, and verify resiliency of infrastructure and applications, so can SOCs look to new methodologies to validate integrity of logging, tools, platforms, analysis and re-enforce forensic tradecraft, as they incorporate automation tools into their arsenals. Chaos Analyst is a new methodology for SOCs which looks at implementing scenarios that force analysts to overcome obstacles that impact their ability to address alerts, or in more advanced scenarios, validate potentially compromised logs and data. This can be incorporated into red team activity to mimic more sophisticated attackers and manipulation, improving the ability of response, the tradecraft and preparedness of the SOC in detecting and preventing actors from compromising all elements of the business.
Chaos Engineering #
While working for Netflix in 2011, Greg Orzell developed a tool called Chaos Monkey. The principle was to test and verify the resilience of Netflix’s IT infrastructure through intentionally disabling computers, in doing so identifying how the remaining systems would function. The intent was to move away from a development model that assumed no breakdowns, and shift to one where breakdowns were considered to be inevitable, therefore forcing applications to build in resilience to handle such incidents. The concept could be related to the idea of a monkey being let loose in a data centre randomly hitting power buttons on systems.
Since then the concept has evolved into the field of chaos engineering, a discipline of experimenting on a software system in production in order to build confidence in the system’s capability to withstand turbulent and unexpected conditions.
The Automated SOC #
As SOCs are gaining access to more sophisticated tooling, and driven by the MITRE ATT&CK model, SOCs are developing more diverse alerting and detections, but in doing so are facing new challenges. While their visibility is increasing, this now comes at the cost of an exponential increase in alerting. SOCs are having to the shift to a DevOps methodology to rapidly respond and develop new alerting and detection rules, which in turn are creating an extreme volume of cases for analysts to work on. As such this is driving SOCs to investigate how they can operate at scale, driving them towards automation tools to automate as much as possible, re-enforcing the DevOps methodology within the environment, and replacing the valuable forensic tradecraft and incident response knowledge with that of automation platform tooling and programming.
As automation platforms and Security Orchestration, Automation, and Response (SOAR) now taking front place for analysts, the question was asked what would happen if such a critical system was impacted in the first place? Which is the same question that Chaos Engineering was attempting to answer in the first place. If your triggers for automated playbooks are no longer coming in, what will happen when that feed is restored? Will there be a gap in analysis in which an analyst could have been deceived and lead to an incorrect conclusion? Or can we store those and replay back that activity, in which case we now need to incorporate a queuing system which increases the complexity when diagnosing issues What about for playbooks being tampered with, or altered to not fulfil the intended actions when executed? Or for time critical applications, whereby by not acting sooner you potentially miss critical information? What about cases of outages of such a long window it’s simply not feasible to wait? It’s simply not feasible for analysts to just idly sit by while malicious activity are potentially being triggered.
One thing I’ve noted among SOC analysts who have been inundated with some sort of detection alert is forgetting what they represent; each alert is supposed to represent an independent action of malicious or unwanted activity. This is just an evolutionary mechanism, as teams start to increase their maturity they start to bring on additional logging sources, tools, or platforms to help increase their visibility, and in turn start finding themselves flooded with benign or activity considered trivial. Analysts get fatigue from the increased amount of alerting they’re seeing, or negate alerts without remediating the cause in desperation to not ruin SLAs. This leads teams to try and fine tune detection logic in an attempt to curb the volume of alerts, but this is a difficult balance, and what is really being done is removing detection alerts altogether. The reality is that the detection alerts reflect something important, otherwise why alert on it in the first place? When inundated with supposedly benign detection alerts analysts can tend to forget the potential impact they represent, and lead to them becoming disillusioned to alerts.
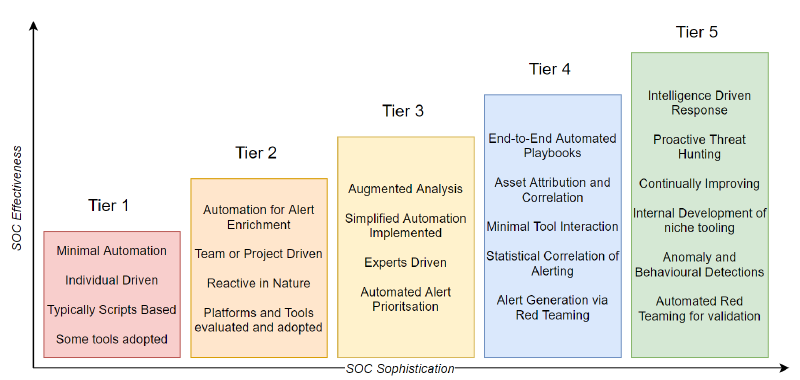
This analysis paralysis to alerts seen as trivial lends itself into the automation model - as the SOC scales, the alerts themselves become overwhelming, even after fine tuning and prioritisation, so teams look to automation to tend to the simpler matters letting analysts investigate and hunt more sophisticated cases that aren’t as clearly defined, maintaining their interests and helping identify and incorporate new detection alerting.
Chaos Analyst #
With the prominence of automation gaining traction in the workforce, SOCs are shifting to automation to assist in scaling the response. As such analysts are transitioning from detailed host and network analysis to platform usage. As a result the forensic tradecraft and skillsets of analysts are shrinking due to simply not being used. While the idea of the automation maturity model is to transition an analysts skillset from incident response into threat hunting, intelligence and possibly more red or purple teaming, in my experience analysts tend to struggle with these exercises as they’ve lost familiarity with the skillsets and tradecraft that make these activities possible.
The idea of chaos analyst is to take the learnings from Chaos Engineering, and apply them to a SOC environment. In doing so we gain the additional benefit of re-developing the lost tradecraft of analysts, start building red teaming activities, ensure that analysts experience the variety in cases to prevent case fatigue, establish the criticality of fundamental SOC systems, identify possible impact to SLAs, and help uncover key detections that can be created to identify sophisticated malicious attackers attempting to sabotage systems.
The implementation of the idea is simple, impact one of the tools, and see how analysts go about identifying the issue, investigating and resolving the case to remediation. Because of the scope, initially this could start from a basic scenario such as disabling a tool, but range up to more advanced scenarios such as a red team sabotaging and feeding false data to hide more malicious activities. The tool or platform in question could range from the analysts workstation, to mission critical Security Incident Event Monitoring (SIEM)/Security Orchestration, Automation, and Response (SOAR), to endpoint platforms and tools that feed those Security Incident Event Monitoring (SIEM)/Security Orchestration, Automation, and Response (SOAR). There’s no doubts that such an impact will also impact key metrics, but this can re-enforce the critical role the system plays for the SOC, re-enforcing resources required to ensure such metrics aren’t impacted.
Procedure #
If we examine a SOCs tooling, platforms and alerting from an end-to-end perspective we can establish a distance vector for visibility of analysts; the less interaction an analyst has with a tool, platform or system the harder it will be for an analyst to establish an issue. While Chaos analyst works on the premise that everything is in scope for sabotage, when starting a chaos analyst scenario we look at the closest interaction zone that an analyst typically interacts with, ranging from Security Incident Event Monitoring (SIEM), Security Orchestration, Automation, and Response (SOAR), analyst workstations, case management systems, knowledge-bases and more. The idea being that because they directly interact with it, they have greater visibility over the system and therefore will be able to identify and overcome the obstacle quicker, whereas as you shift further away from the analysts visibility, it’ll be harder for an analyst to detect, respond and mitigate.
Start simply by examining the closest component that an analyst interacts with - their workstation. Remove the power cable, or a critical hardware component, if you have a business continuity plan an analyst should revert to this. In doing so this provides an additional benefit, in validating and verifying the business continuity plan. As such simple tests are overcome, we increase the complexity - network contain the host so they’re unable to communicate out to any tools, disable their account or more - would they be able to handle such situations?
As a SOC with an automation platform we can leverage that to instigate and implement chaos analyst scenarios, therefore providing a simulation we can repeat automatically, without taking up resources beyond the initial investment. The automation platform is there to assist and augment the SOC, but that scope goes beyond simple playbooks - with some creativity and imagination we can validate controls, detections, alerting pathways and more, especially through methodologies like chaos analyst. On top of that the developers who are building the playbooks understand them best, they understand the processes they go through, the potential points of failure or conditions that can go wrong, they have to factor that in when developing playbooks, and systems like Chaos Analyst can help them understand those points better and build in better redundancy. Like Chaos Engineering, SOCs need to shift away from the idea of their alerting being unable to break down, to identify when it has, so that backup plans can ensure that the business continues.
As the team adapts to the adverse conditions, we can start extending beyond their immediate visibility scope. Disable their access to Security Incident Event Monitoring (SIEM)/Security Orchestration, Automation, and Response (SOAR), create automation runbooks that’ll create false alerts, or that would suggest there are faults within the Security Orchestration, Automation, and Response (SOAR). Automation is a powerful tool to help our SOC scale, but it can also be a powerful means to help coordinate Chaos Analyst scenarios. Again we take the same premise as before, starting simple, but then as the team finds themselves reconciling events, we can increase the complexity. Incorporating automation playbooks can also extend the scope and abilities ranging from failing outright, to soft failing and providing invalid information. Now it’s up to the analyst to go to the source to uncover that information, and possibly execute remediation manually.
Proceeding further we then look at the endpoint where the original alert was created, as well as the log traversal mechanism themselves. Here we have a wider scope of things that can go wrong, or of scenarios we can envisage for a chaos analyst scenario. This could range from simple scenarios like logs being rotated out and lost, to a malicious actor purposefully masking activity. In the former advanced scenario, this is where we can start leading into interactions with red teams.
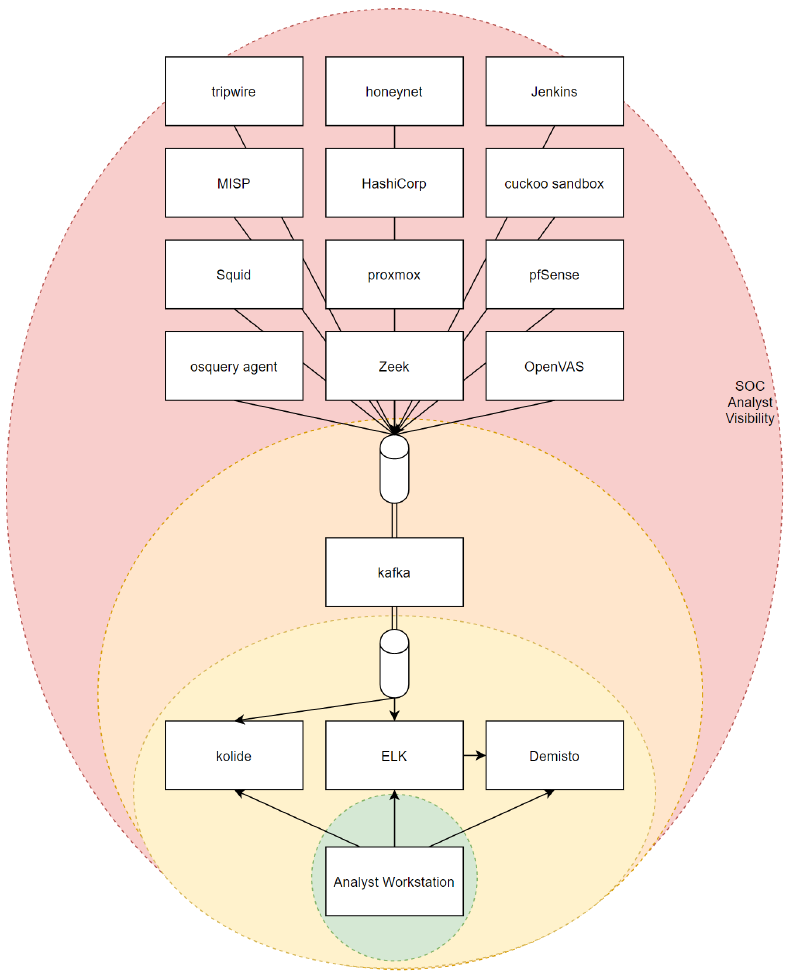
When looking at a red team scenario for chaos analyst, we’re not looking at covering a single facet - we’re examining the entire flow, similar to the MITRE ATT&CK model. SOC Analysts are highly valuable targets, simply due to the visibility across the infrastructure their monitor and protect, so for a sophisticated attacker it makes sense to cover their own tracks (counteracting the SOC), and in extreme measures possibly trigger a minor or trivial alert on a host to attempt to identify and record the response from the SOC.
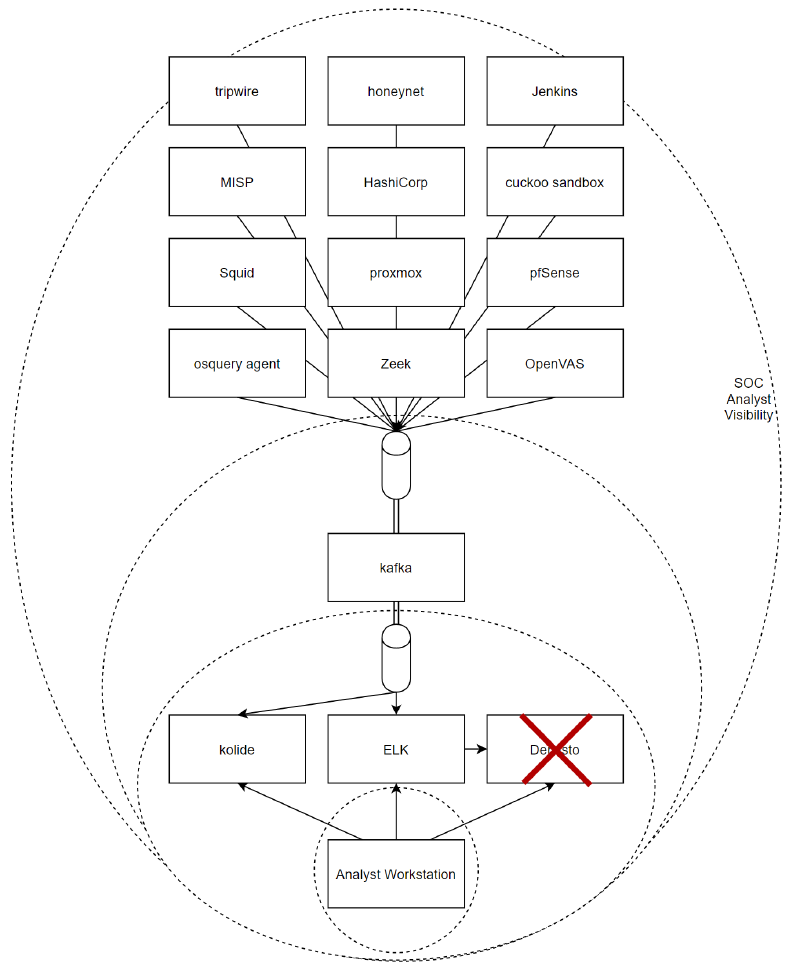
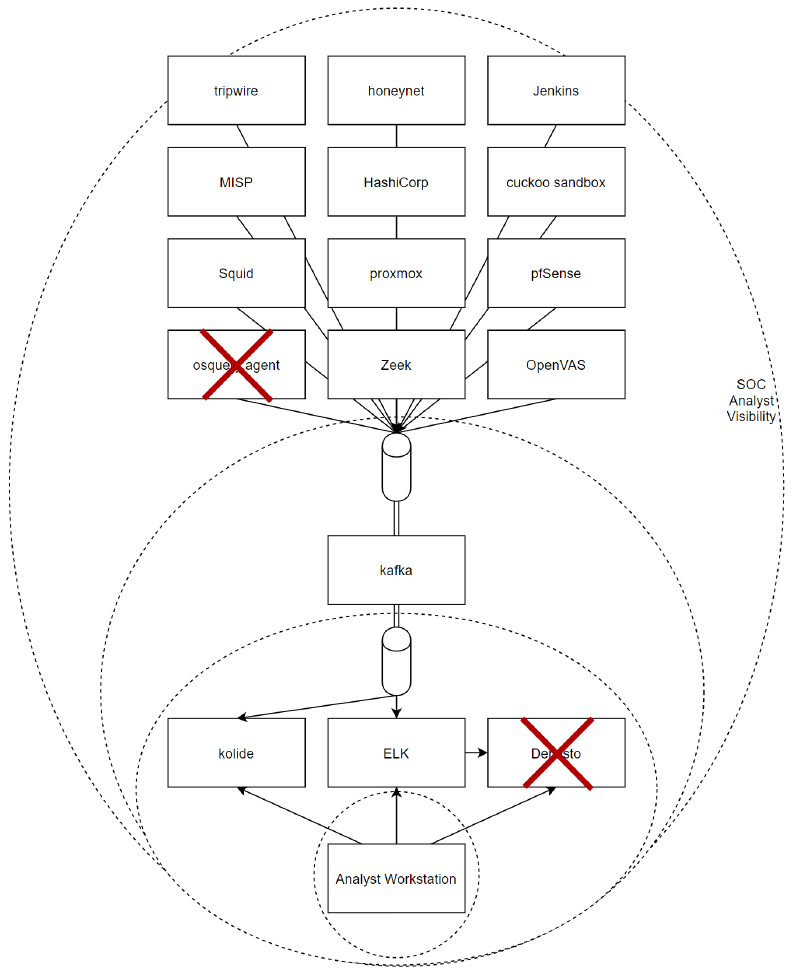
As such a Chaos Analyst scenario would look at implementing a multitude of the scenarios that we’re covered so far, not just limiting themselves to disabling or crippling a single tool, but going to the full extreme of tampering with elements along the entire flow, or outright disabling/triggering alerting to protect the malicious actor, and identify SOC analysts.
The hardest difficulty is when initially starting out, you do not necessarily want to impact the entirety of the SOC, therefore you want to start small targeting a single analyst out of the pool, so that normal SOC operations aren’t drastically impacted. If you find that they have been impacted through just a single analyst, then we’ve already identified scope for improvement.
Red/Purple Teaming #
In recent years evidence has been uncovered showing the increase in the sophistication of adversaries, as such organisations are attempting to shift to respond to such threats. While SOC analysts are inundated with basic attacks, that same firehose of alerting can help mask more subtle infiltration. With Automation helping SOCs scale out and tackle those more repeatable actions, it now gives them more time to hunt for more cultivated and refined advanced persistent threats. Chaos Analyst helps teach SOC analysts how to identify a malicious attacker looking not only to disable evidence collection, but also more subtle sabotage in the form of tampering logs, tools or products. In such cases expected logs or canary alerting are still generated, but such as to hide any evidence of an endpoints compromise. In this case we’re using the red team to masquerade as those sophisticated advanced persistent threats, undertaking the kind of activity that SOC analysts may struggle with.
There are a multitude of scenarios that a red team can cover in a chaos analyst scenario, starting with basic actions such as disabling or cleaning up logs in an attempt to hide activity, shifting towards falsely generating alerts to camouflage their own activity and initiate a denial of service against a SOC, or the most extreme and dangerous situations such as being discovered and instantly switching to a scorched earth through data destruction. A prime example of the kind of sophistication I’m talking about was seen in the analysis of stuxnet: not only did stuxnet showcase that advanced persistent threats were targeting hardware appliances like routers, switches and SCADA platforms, stuxnet had the ability to record legitimate data over a window of time, then while impacting systems, play back that legitimate data to monitoring systems, completely blindsiding the technicians into believing all systems were acting as intended while secretly destruction was taking place.
We haven’t even covered scenarios involving insider threats - where a rogue SOC analyst could be masking their activity by impacting other analysts. A red team implementing chaos analyst can help highlight and implement such scenarios. At the end of the day analysts will only be as successful as the data they receive, and in an environment where everything can be hostile, including other analysts, it’s the duty of SOC analysts to identify when there are attempts to tamper with that evidence and data.
At the end of the period, all good red teaming activities feature a retrospective session at the conclusion, where blue and red teams come together to share targeted systems, goals and uncovered activities and information from both sides. The goal of which is to help each party improve with each cycle. In undertaking this activity it drives the blue team to detect and protect against more sophisticated attacks, while also forcing the red team to devise more cultivated methods for access, both of which strive to benefit the business as a whole. Even if a blue team is unsuccessful in a Chaos Analyst activity, it just highlights a need for improvement, and provides a pathway to that improvement.
Conclusion #
The idea behind Chaos Analyst is not for a SOC struggling to get monitoring in place, or are in the midst of building automations, rather it’s for a SOC looking at to establish and advance their threat hunting and intelligence capabilities. It’s fundamental that the basics such as good coverage and visibility of its environment are in place, and helps for SOCs to continue to evolve. If you don’t have core visibility issues cemented before attempting such a venture then you’re not going to take any value from the lessons, because the lessons will simply revolve around those basics. But for those SOCs that are at the sophisticated end of the automation model it provides a mechanism to re-enforce and educate SOC analysts, develop more sophisticated alerting relating to evidence tampering, explore threat hunting and intelligence gathering, establish a red teaming program, and to identify the criticality and vigilance of SOC systems.
Resources #
- Top 5 best practices to automate security operations
- Principles of Chaos Engineering
- An Unprecedented Look at Stuxnet, the World’s First Digital Weapon
- Stuxnet Used an Old Movie Trick to Fool Iran’s Nuclear Program
- Script Recovers Event Logs Doctored by NSA Hacking Tool
- ATT&CK Matrix For Enterprises